Seven fix types. Every gap has exactly one.
When Rankwize diagnoses a gap, the result isn't a vague recommendation — it's one of seven fix types, assigned deterministically from the gap evidence. You see which type the gap maps to, which dimension failed, and what to do next.
Available on Pro + Diagnose and above
The seven fix types.
When Rankwize diagnoses a gap, it compares your matched page against the competitor page currently being cited across five evaluation dimensions: freshness, evidence strength, structure and extractability, audience fit, and CTA quality. The dimension scores map to exactly one primary fix type — with up to three secondary recommendations per failing prompt.
Update Existing
FreshnessYour page is being cited, but the content is outdated or lacks the structure AI engines expect.
Add Evidence
Evidence StrengthYour page is being cited, but the competitor page carries proof objects yours doesn't — data, case studies, third-party references.
Create Comparison
No matching pageA competitor has a comparison page for this query and you don't. The fix is a net-new comparison piece.
Create How-To
No matching pageThe default creation type for informational, commercial, and navigational intent prompts where your content library has no matching page.
Create Diagnostic
No matching pageDiagnostic-intent prompts with no matching page. A narrower creation path grounded in the question-and-diagnosis framing of the query.
Improve CTA
CTA QualityYour page is being cited, but the CTA doesn't match what the prompt's query intent expects.
Offsite Seed
Lower-priority promptsFor lower-priority prompts where creating a net-new page isn't the right call. The fix is earned placement in a third-party property already cited for this prompt type.
Fix type distribution across diagnosed gaps — this tenant's top gap is Add Evidence.
Deterministic, not inferred.
The fix type assignment runs a decision tree, not an LLM judgment call. The match outcome combined with the five gap dimension scores produces the fix type assignment directly. The same inputs produce the same output every time.
Input A
Match outcome
Strong match, borderline, or no match — determined by the 7-signal content library scorer.
Input B
Dimension that failed
Freshness, evidence strength, structure, audience fit, or CTA quality — the weakest score determines the path.
Output
Fix type assigned
One primary fix type. Up to three secondary recommendations. Every recommendation links back to the specific dimension failure that drove it.
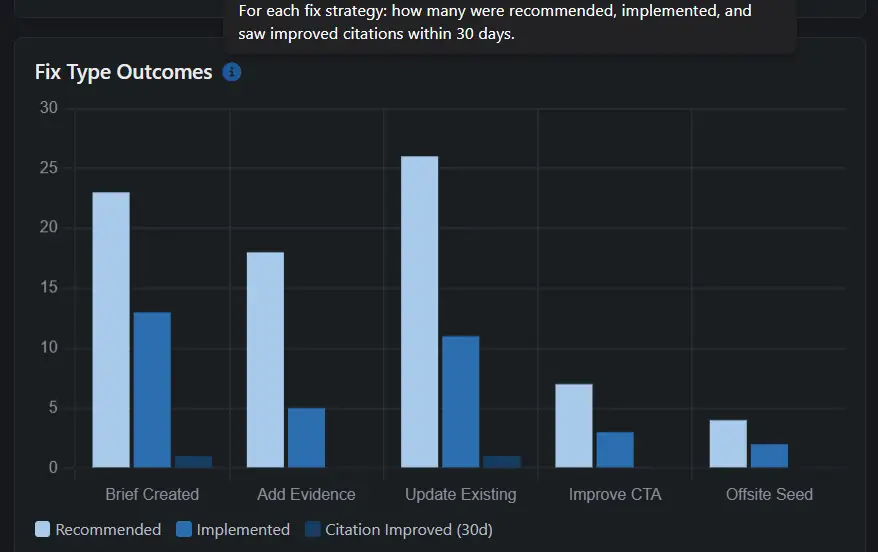
Fix Type Effectiveness — it learns from your data.
Every verified recommendation contributes to a 180-day rolling effectiveness score per fix type for your tenant. Fix types running below 50 percent effectiveness get demoted in future recommendations — down to a floor, never dropped entirely. The fix types that keep working for you hold their rank and rise to the top.
The score is tenant-specific — it learns from your verification data, not benchmarks from other customers. The longer you use Rankwize, the more the recommendation engine weights the fix types that actually work for your content and audience.
Effectiveness scores are visible on the Impact Tracker surface.
<50%
Demoted
Fix types below this threshold are ranked lower in future recommendations for your tenant.
30%
Floor
Effectiveness is clamped to a 30% floor — even a struggling fix type is never fully suppressed, so it can recover if it starts working again.
180-day rolling window
Old verification data ages out. The effectiveness score reflects recent performance, not a static average from your first month.
How it works
Diagnose
Rankwize scores your matched page against the currently-cited competitor page across five gap dimensions.
Assign
The decision tree maps the dimension scores to exactly one primary fix type, plus up to three secondary recommendations.
Learn
Every verified recommendation updates your 180-day effectiveness score per fix type, adjusting future assignments toward what's working for your tenant.
Fix Type Taxonomy is one pillar of the Rankwize Diagnose engine.